With the maturation of large model
capabilities and breakthroughs in multimodal interaction technology, AI glasses
are no longer just a lightweight branch of AR/VR; they are being redefined as
the "next-generation core hub for human-computer interaction." User
expectations for AI glasses have evolved beyond simply "hearing" to a
four-level hierarchy: "From hearing, to audibility, to clarity, to
comprehension":
· Hearing – The microphone completes basic sound capture.
· Audibility – Ensuring sufficient volume and undistorted
original sound.
· Clarity – Effectively separating human voice from ambient
noise.
· Comprehension – Relying on AI to accurately
interpret user intent.
Currently, most devices only reach the
second stage, with a few achieving voice noise separation. Very few products
enable AI to accurately understand commands. Full-link system-level synergy is
becoming the new industry standard.
AWINIC is deeply exploring user pain
points and empowering leading AI glasses products in the industry. With its
core technology of "uplink capture – mid-end optimization – downlink
output – full-link synergy," AWINIC has connected all four stages. By
deploying a rich portfolio of product categories, AWINIC is driving smart audio
devices from merely "producing sound" to "sensing and enabling
interaction." How does AWINIC achieve this? Through "uplink +
downlink" algorithms.
I. AI Glasses
Uplink Audio Solution – Dijiang™ X1
Uplink Audio: Sound Capture and Upload
01 Pinpointing
the Pain Points:
User expectations for essential
scenarios such as real-time translation, first-person recording, AR navigation,
and accessibility assistance are continuously rising. Can you record a vlog
outdoors in high winds? Can you make a phone call in a noisy environment? Can
you hear commands clearly amid the rumble of the subway? AWINIC is deeply
exploring user pain points and empowering leading AI glasses products in the
industry.
02 The Key to
Breaking Through: AWINIC Dijiang™ Uplink Algorithm
AWINIC Dijiang™ is a series of uplink
audio algorithms launched by AWINIC, targeting scenarios such as recording,
video capture, and calling. It offers multiple solution suites, covering core
algorithms including wind noise reduction, surround sound, noise cancellation,
echo cancellation, and beamforming. It supports integration with various
mainstream platforms, allowing flexible combination of algorithm modules based
on different scenario needs, comprehensively empowering AI glasses for diverse
use cases such as outdoor travel, conference calls, and daily recording.
1. 🌬️ Vlog Scenario Empowerment: Fearless Against Motion Wind
Noise, Voice Remains Clear and Transparent
Have you ever experienced such regrets?
🚴🏻♀️ Cycling, with
the wind roar drowning out your inner monologue;
🏃🏻♀️ Running while
filming, gasping and voice becoming indistinguishable;
🚶🏻♀️ Walking
outdoors, rich ambient sound but missing the clarity of that sentence, "I
want to tell you"?

Figure 1: Motion Wind Noise Scenario
Demonstration
🌀 To address this,
AWINIC Dijiang™ has developed a new proprietary wind noise algorithm for AI
glasses:
Acoustic signals captured by the
microphone array pass through the wind noise algorithm, which accurately
identifies wind noise and enhances speech clarity. Then, the surround sound
module enhances the sense of immersion, redefining the sound aesthetic of
vlogs.
With it, even strong winds are not a
problem — every frame is matched with clear, warm sound.
· Status Detection: Transmits noise flag.
· Optional Modules (within dashed circles): Non-essential,
for lightweight needs.
· Implemented (AWINIC blue background): Implemented
modules.
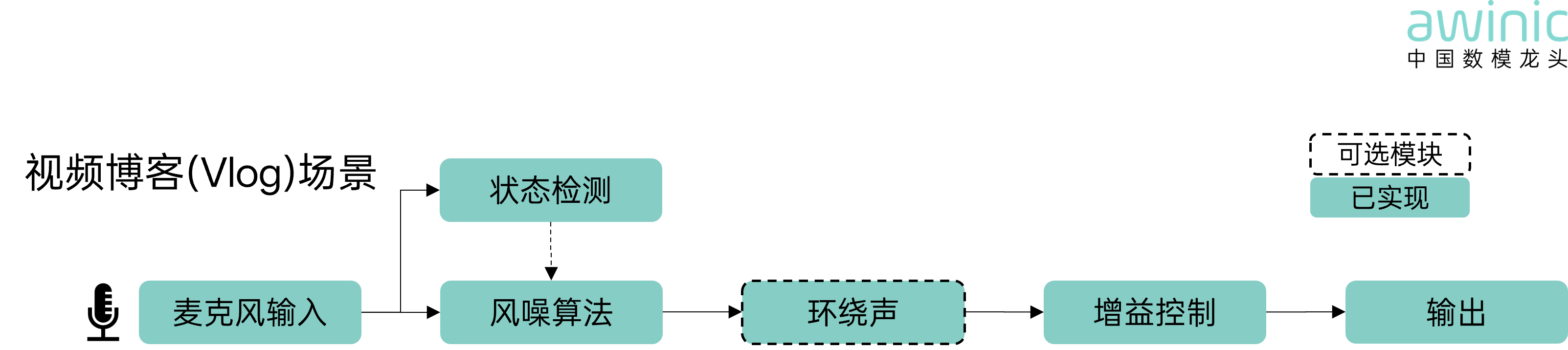
Figure 2: Vlog Scenario Algorithm Block
Diagram
Effect Demonstration
① Wind Noise Algorithm Excels in Different Environments
✅ No wind
& Light wind | Intelligently builds an immersive surround sound
field, giving everyday conversations a cinematic sense of space.
✅ Strong wind | Preserves ambient sound
while improving voice signal SNR. Not "muting," but allowing the
voice to emerge from the noise, turning the atmosphere into texture.
2. 🌐 Full-Scenario Call Empowerment: Intelligent Noise
Cancellation, Precise Voice Transmission
Have you ever had moments like these?
💻 During a video conference, your voice sounds muffled,
and a colleague frowns, asking, "What did you say?"
🕶 Taking an important call on a busy street, with traffic
roar and horns blaring, the other person only hears a "buzz——";
📝 Communicating abroad in a noisy environment, a clerk
enthusiastically introduces spinach: "Do you like spinach?" but the
translation tool interprets it as "You look like a Spaniard"...

Figure 3: Translation Scenario
Demonstration
📞 To address
this, AWINIC Dijiang™ delves deep into the full-link acoustic scene of calls:
Acoustic signals captured by the microphone
array are precisely stripped of echo signals by the echo cancellation module.
Beamforming acts like an invisible spotlight for sound, dynamically locking
onto the sound source direction and narrowing the effective pickup area.
Finally, noise cancellation blocks external noise, delivering an ultimate
calling experience with minimal voice distortion.
· Status Detection: Transmits noise flag.
· Optional Modules (within dashed circles): Non-essential,
for lightweight needs.
· Implemented (AWINIC blue background): Implemented
modules.
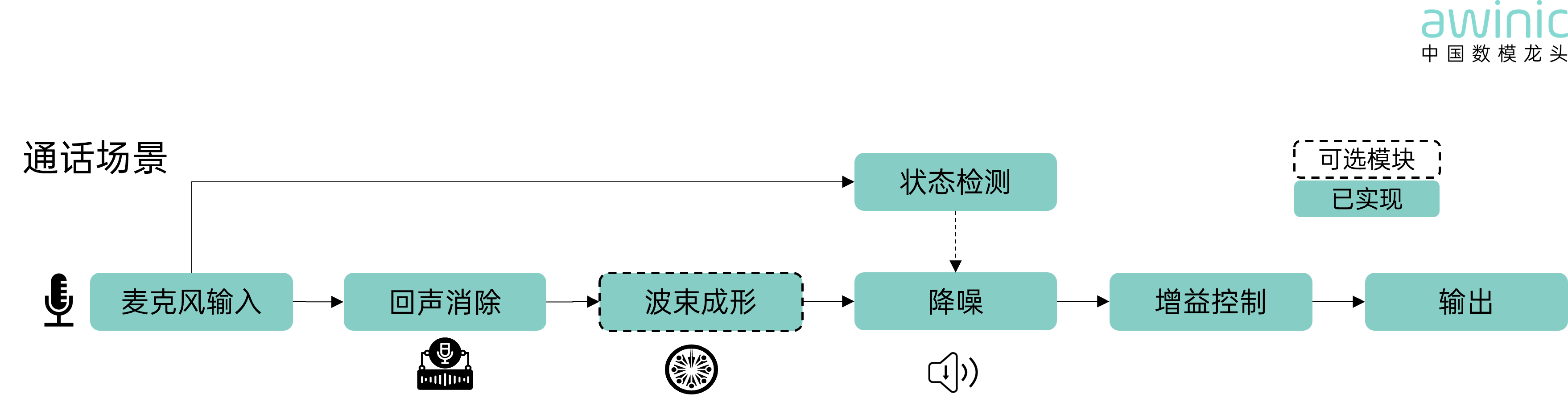
Figure 4: Call Scenario Algorithm Block
Diagram
3. 🗣 The "First Neural Hub" for Wake-up and
Recognition
Have you ever experienced these moments?
🚇 Wearing glasses on the subway, trying to ask about the
weather, but the wind noise drowns out your voice;
☕ Chatting with a friend in a café, you just say "Hey——,"
and the AI glasses mistakenly wake up;
🕺🏻 Strolling and casually calling out, but
the system takes two seconds to respond...

*Figure 5: Voice Wake-up Scenario
Demonstration*
🎤 So AWINIC
Dijiang™ arrives. The front-end voice gatekeeper designed specifically for AI
glasses:
It enhances the speech signal-to-noise
ratio in complex environments (wind noise, human chatter, reverberation). In
real-world wearing scenarios, recognition stability is significantly improved,
with a character error rate reduction of over 6%.
· Optional Modules (within dashed circles): Non-essential,
for lightweight needs.
· Planned (gray background): Future roadmap.
· Implemented (AWINIC blue background): Implemented
modules.

*Figure 6: Wake-up Recognition Scenario
Algorithm Block Diagram*
⏳ Waking up is no
longer just about "being able to trigger." Not waking up is
frustrating, false triggers are awkward, and slow responses are exhausting.
User experience is the sole judge. In the future, AWINIC will develop voice
wake-up algorithms with ultra-low power consumption and ultra-high wake-up
rates — quieter, sharper. After all, the best interaction is one where you
don't even realize it's working.
II. AI Glasses
Downlink Audio Solution – awinicSKTune® Immortal Algorithm W1
Downlink Audio: Sound Playback and
Output
01 Pinpointing
the Pain Points:
Speakers in AR glasses are typically
placed in the temple arms. For aesthetics and portability, the cavity space is
extremely tight. The driver weighs less than 2 grams, with dimensions ≤10×18mm
and thickness ≤3.5mm. Due to these physical constraints, such micro-speakers
suffer from weak volume and low-frequency performance. Dual drivers produce
sound independently, making it difficult to achieve a surround sound field,
while also being prone to noticeable airflow artifacts. Therefore, when AI
glasses play music, the sound quality is thin and weak, lacking bass and
immersive surround sound. How can this be solved?

Figure 7: Speaker Placement Diagram
(Single Side)
02 The Key to
Breaking Through: awinicSKTune® Immortal Algorithm W1
AWINIC's awinicSKTune® Immortal
Algorithm W1, with its exceptionally simple yet effective algorithmic
performance, is the core key to solving these problems.
Figure 8: awinicSKTune® Immortal
Algorithm W1 Sound Processing
Figure 9: Traditional Sound Processing
The awinicSKTune® Immortal Algorithm W1
helps smart wearable manufacturers achieve superior low-frequency performance,
lower distortion, and a more immersive audio experience even within compact
layout designs.
· AI Sound Field Surround Technology:
Uses AI element recognition to separate and control different audio components,
then renders the positions of virtual sound sources, simulating the effect of
sound arriving at your ears "from different directions and
distances."
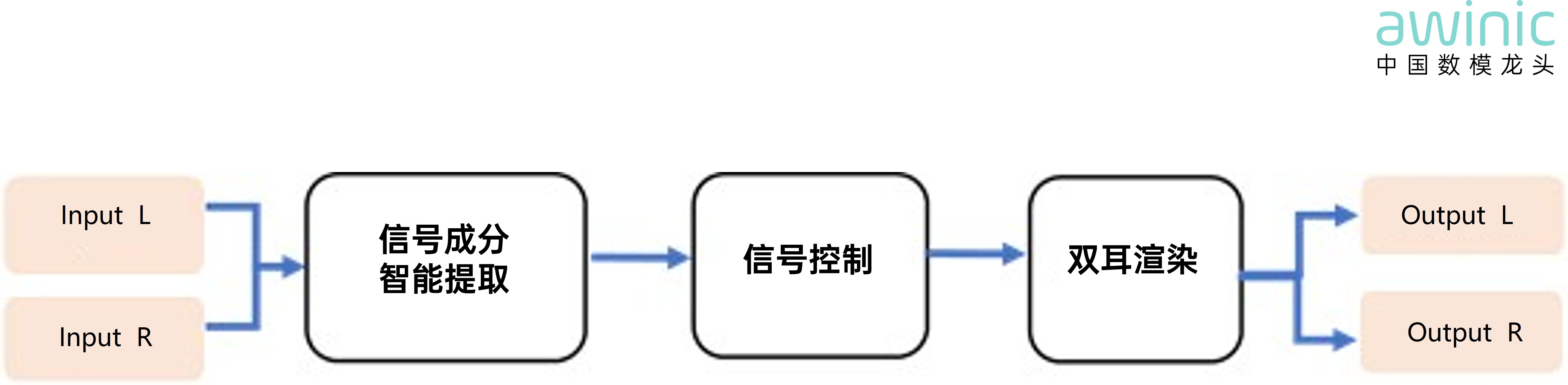
Figure 10: AI
Sound Field Surround Technology
· Bass Enhancement Technology:
Due to their small size and light weight, common AI glasses speakers have a
limited tolerance for low-frequency voltage signals.
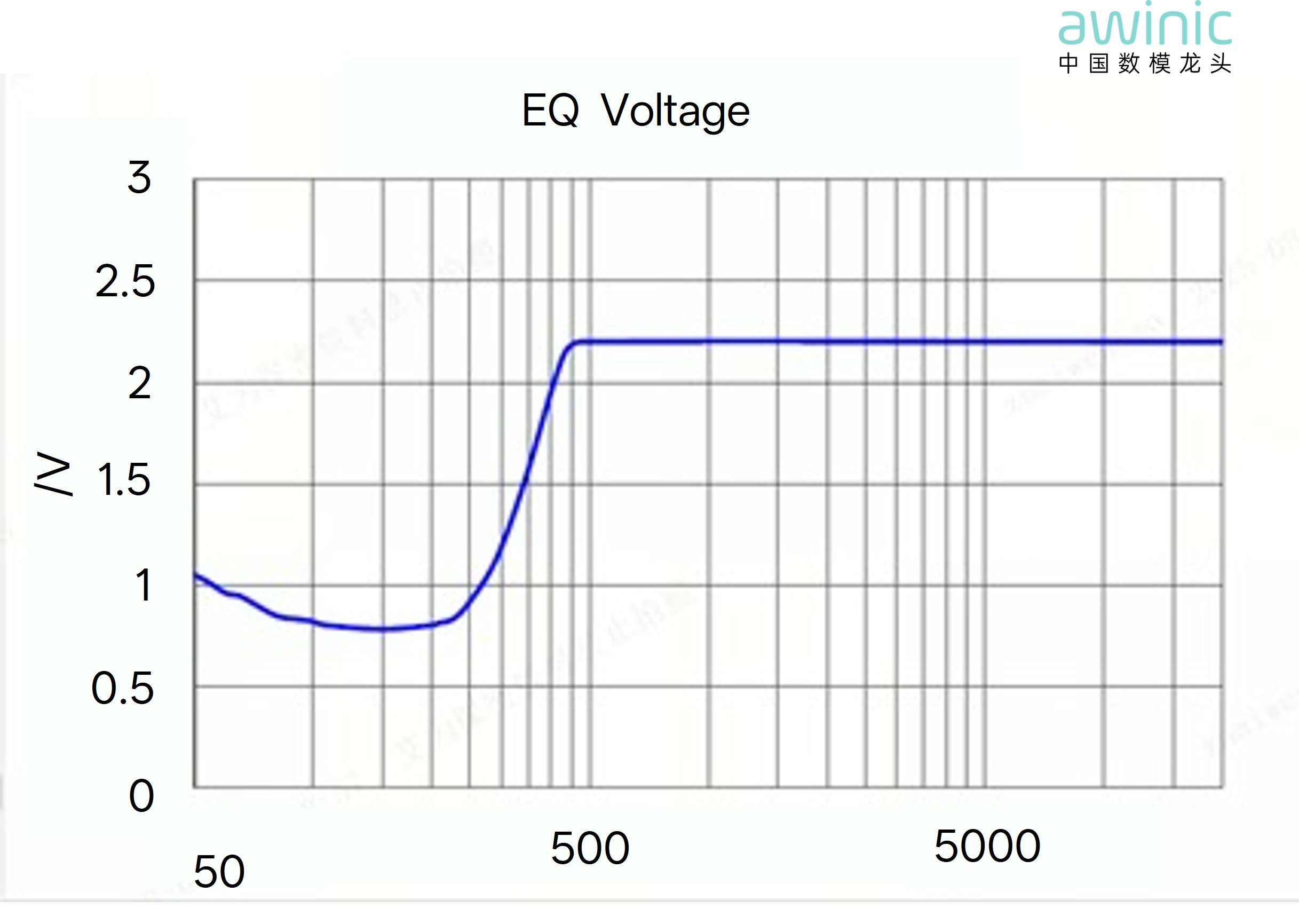
Figure 11: Typical AI Glasses EQ Voltage
Curve
Traditional processing methods only use
EQ high-pass or low-shelf filters for pre-processing to reduce low-frequency
energy and avoid mechanical distortion of the speaker diaphragm. This method
inevitably compromises the overall low-frequency effect, especially the
critical 50Hz-200Hz range.
The Bass
Enhancement technology in awinicSKTune® Immortal Algorithm W1 provides a
complete bass enhancement solution. It establishes a speaker displacement model
curve to ensure all signals operate within a safe amplitude range. Then, it
applies differentiated bass enhancement techniques, balancing the virtual
component perception of large and small signals to improve the low-frequency
performance of drums and vocals.
· Nonlinear Distortion Suppression Algorithm:
Due to magnetic circuit nonlinearity, suspension system nonlinearity, and
breakup modes at large amplitudes, speakers are prone to nonlinear distortion
at high amplitudes. This causes low-frequency buzzing, reduced clarity, and
negatively impacts the listening experience and low-frequency performance. The
nonlinear distortion suppression algorithm repairs low-frequency perception.
Combined with bass enhancement technology, it maintains pure timbre while
increasing low-frequency dynamics.
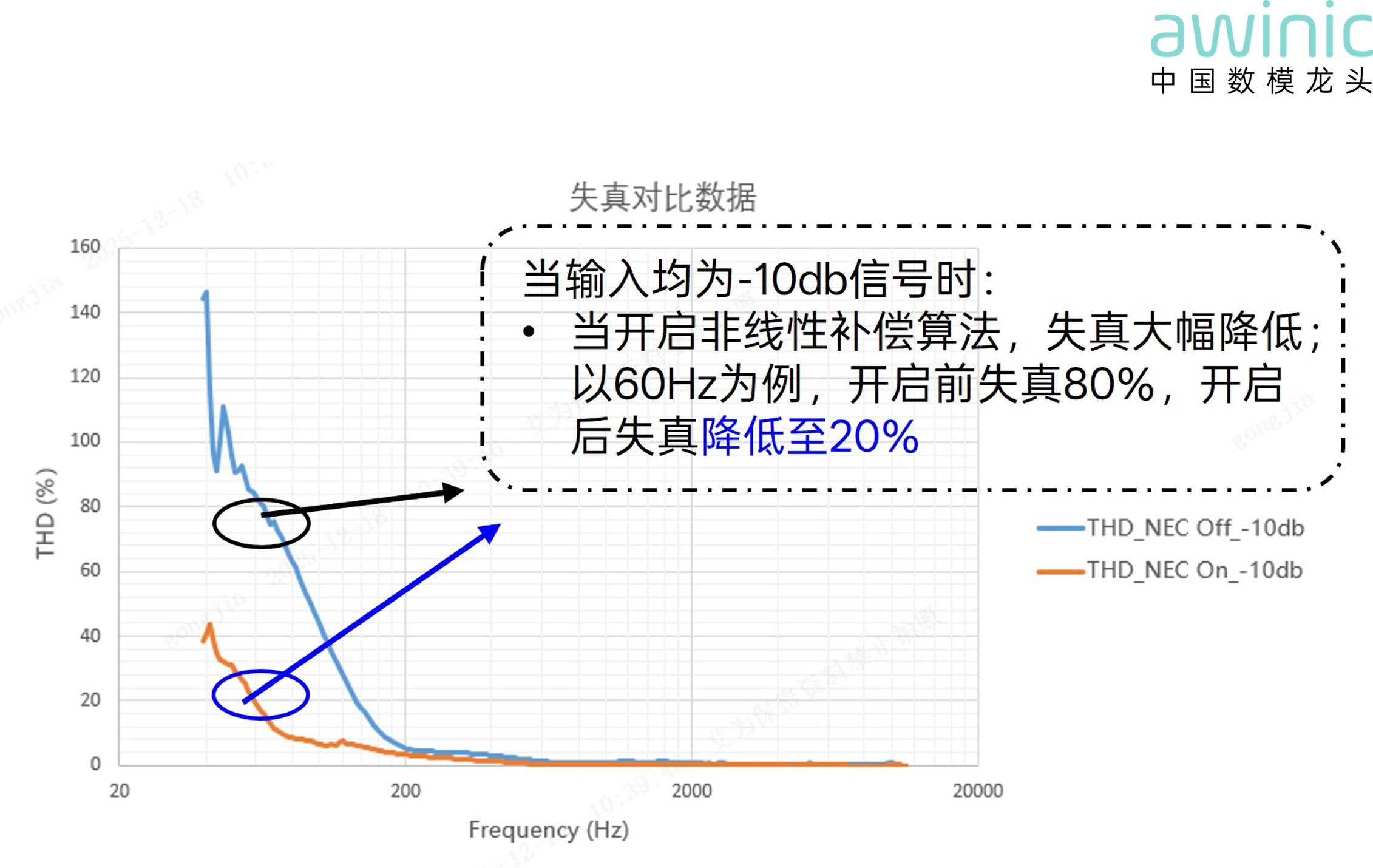
*Figure 12:
Distortion Comparison with NEC Algorithm On/Off (Same Input)*
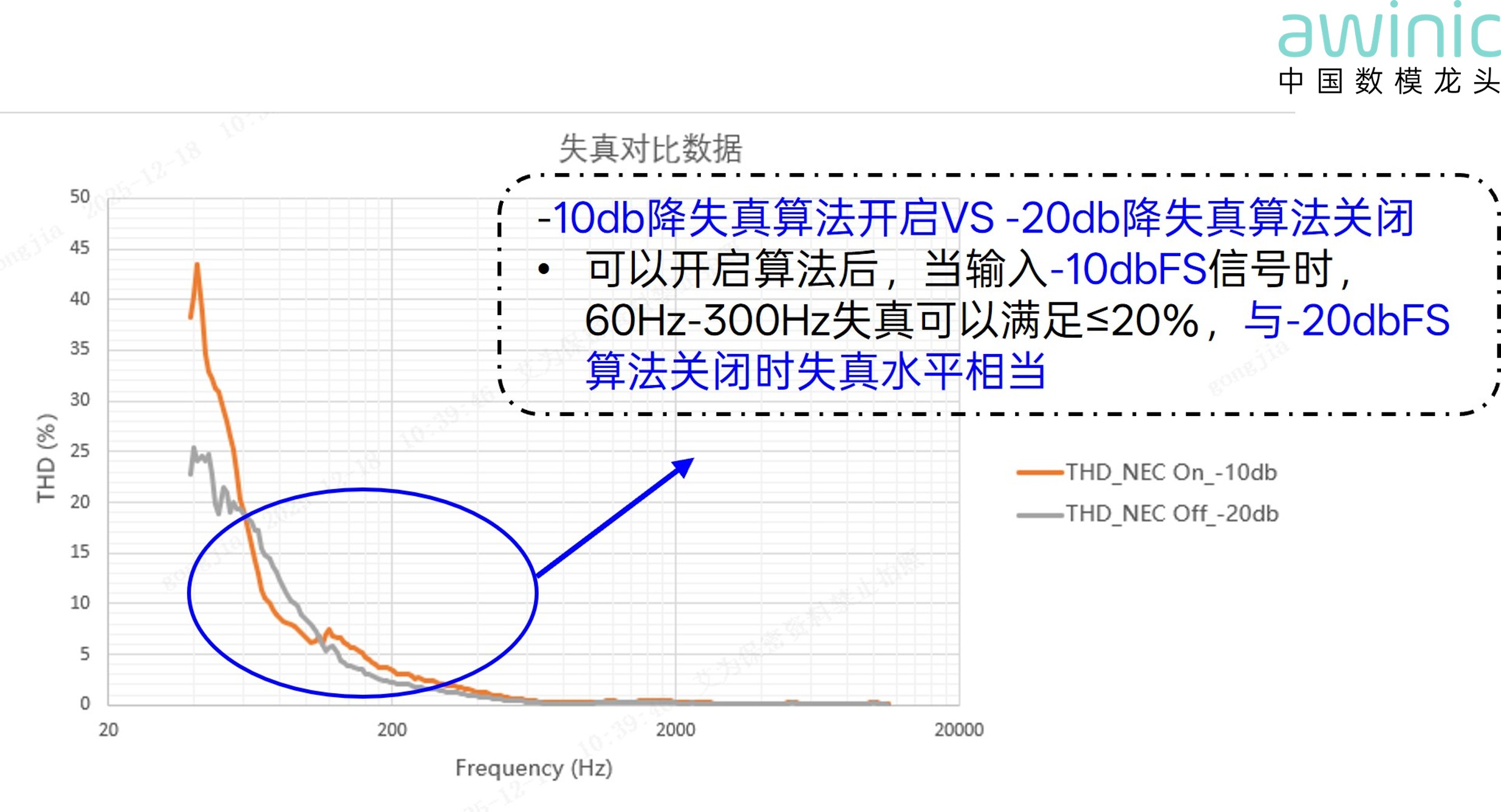
Figure 13: Input Level Comparison at Equivalent Distortion Levels
· Piano Noise Suppression Algorithm:
The APR technology in awinicSKTune® Immortal Algorithm W1 uses AI to
intelligently identify playback audio elements, accurately determining whether
the source will produce airflow artifacts. With flexible processing methods, it
solves the problem of speaker airflow artifacts and piano noise by providing
dynamic compression capability of over 6dB, without sacrificing other audio
elements or bass effects.
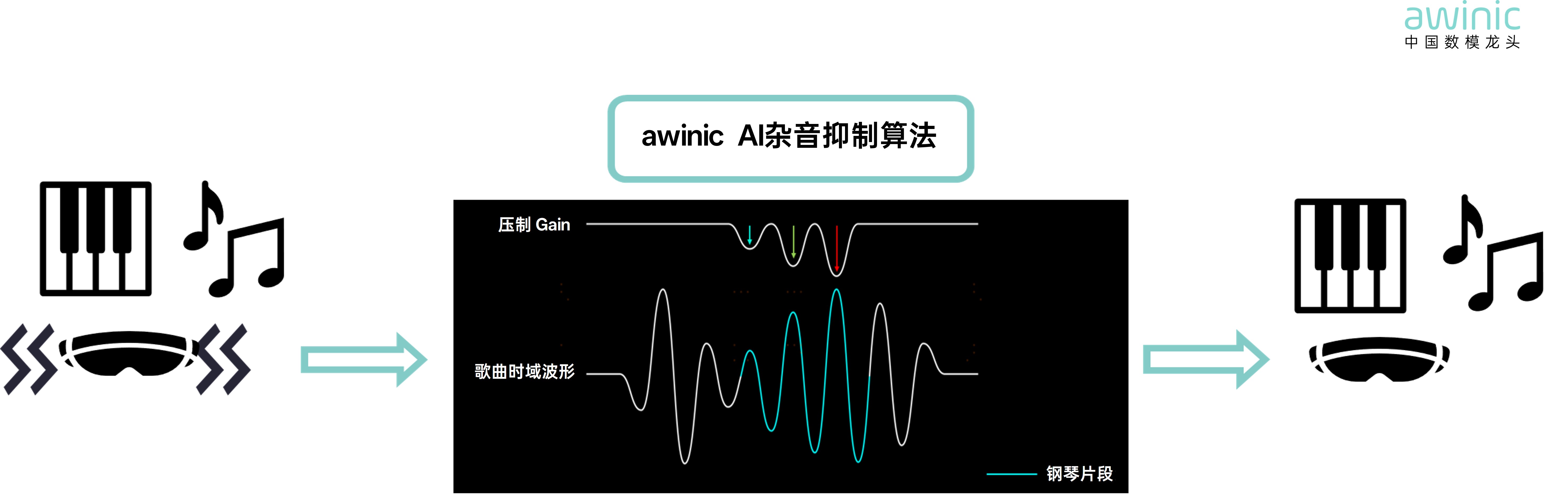
Figure 14:
AWINIC AI Artifact Noise Suppression Algorithm
· Intelligent Volume Control Algorithm:
Poor audibility at high outdoor volumes and lack of low-frequency perception at
low indoor/medium volumes are also common pain points for glasses products. The
intelligent volume control algorithm in awinicSKTune® Immortal Algorithm W1
adjusts the EQ curve in real-time based on volume level information from the
platform side. At low volumes, human ear sensitivity to low frequencies
decreases, so the algorithm automatically boosts low-frequency gain. At high
volumes, to prevent speaker overload, it automatically reduces low-frequency
gain, boosts mid-frequency (voice) clarity, and automatically compresses peaks
to reduce artifacts.
One-click switching and separate tuning
ensure the best sound for every scenario.
Figure 15: Examples of Tuning Styles
Under Different Modes
o Blue Curve (Indoor Sound Quality Mode): Typically
used for scenarios such as music listening. Features balanced performance
across low, mid, and high frequencies, authentically restoring sound details
and layering.
o Yellow Curve (Extra-Loud Volume Mode): Typically
used for noisy outdoor scenarios. Boosts mid and high frequencies,
significantly enhancing voice clarity and penetration.
o
Other desired scenarios can also be defined based on
specific requirements.
Furthermore, the awinicSKTune® Immortal
Algorithm W1 has been successfully ported and functionally verified on major
platforms, making it the preferred audio solution for wearable products.
Good sound
should not be limited by size. As a leading player in both analog and digital
technologies, AWINIC Electronics is committed to empowering next-generation
smart wearables with acoustic algorithms, delivering a high-quality audio
experience to users.






