With the maturation of
large model capabilities and breakthroughs in multimodal interaction
technology, AI glasses are no longer just a lightweight branch of AR/VR.
Instead, they are being redefined as the "core hub for next-generation
human-computer interaction." User expectations for essential scenarios
such as real-time translation, first-person recording, AR navigation, and
accessibility assistance continue to rise. Can you record a vlog outdoors in
strong winds? Can you make a phone call in a noisy environment? Can you hear
voice commands clearly amid the roar of a subway? Awinic delves deep into user
pain points and empowers leading AI glasses products across the industry.
I. Awinic Dijiang™ Algorithm Application Solution
The Awinic Dijiang™ series is a portfolio of uplink audio
algorithms launched by Awinic Electronics. Targeting scenarios
such as audio/video recording and phone calls, it offers multiple solutions,
including core algorithms for wind noise reduction, surround sound, noise
cancellation, echo cancellation, and beamforming. It supports integration into
various mainstream platforms, allowing flexible combinations of algorithm
modules based on different scenario requirements, thereby comprehensively
empowering AI glasses for diverse use cases including outdoor travel,
conference meetings, and daily recording.
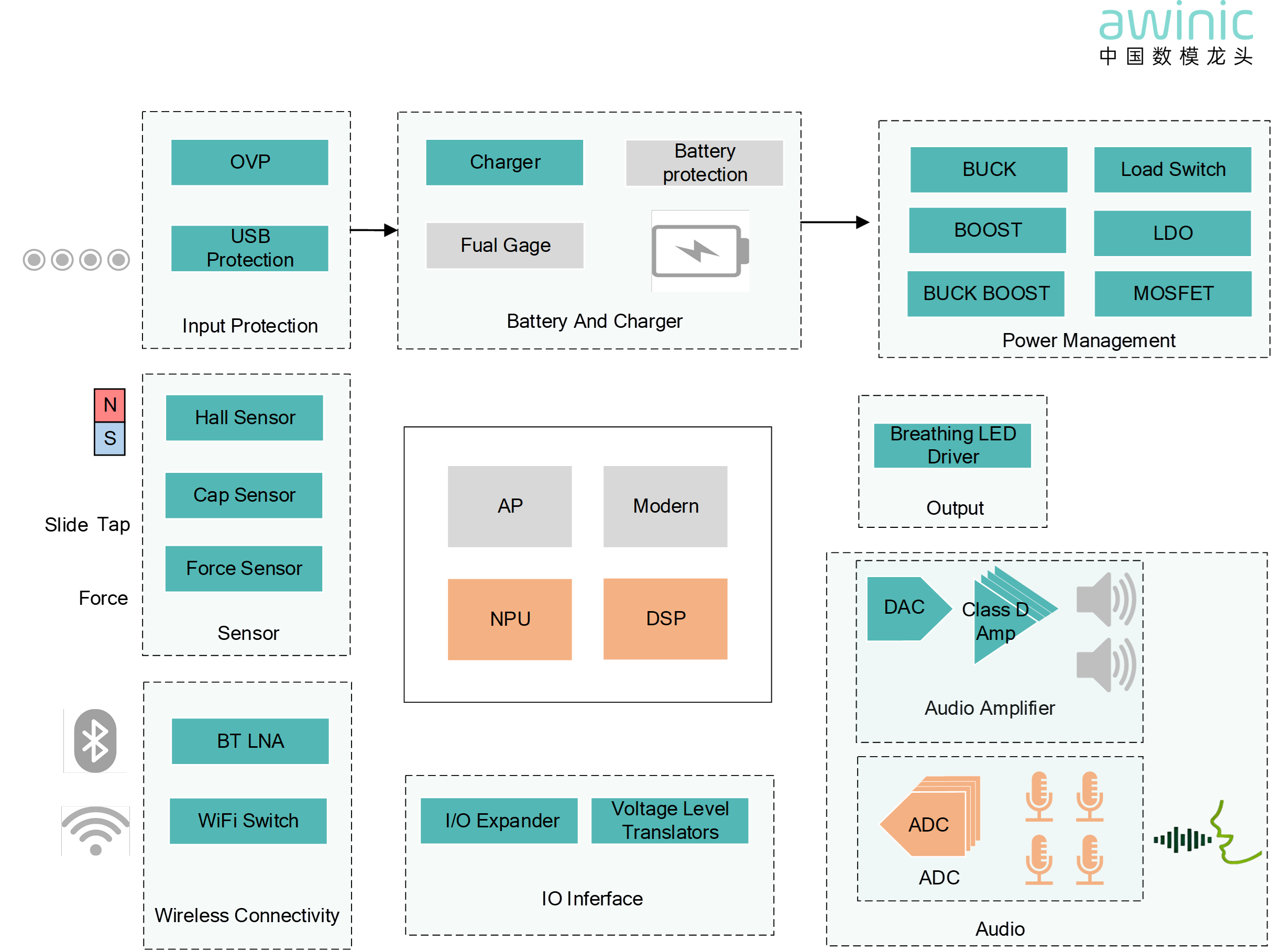
Figure 1: AI Glasses Application Block Diagram
👓 In a
typical AI glasses architecture, acoustic signals captured by the
multi-microphone array are sampled by a high-precision ADC and then fed into
the processing unit in real-time via a low-latency bus. The Awinic Dijiang™ can be flexibly deployed on a DSP or NPU, supporting 2-to-8 channel
multi-microphone arrays.
II. Application Scenarios of Awinic Dijiang™ Uplink Algorithms
in AI Glasses: Examples
1. 🌬️ Vlog
Scenario Empowerment – Clear and Transparent Voice, Unaffected by Motion Wind
Noise
Have you ever had regrets like these?
🚴🏻♀️ During a bike ride, the sound of the
wind drowns out your inner monologue;
🏃🏻♀️ While running and filming, your
breathing and voice become a jumbled mess;
🚶🏻♀️ On an outdoor stroll, the ambient
atmosphere is rich, but the clarity of that one sentence, "I want to tell
you," is missing?

Figure 2: Motion Wind Noise Scenario
Demonstration
🌀 To address
this, Awinic Dijiang™ introduces a newly self-developed wind noise
algorithm for AI glasses:
The acoustic signals captured by the microphone array pass
through the wind noise algorithm, which accurately identifies wind noise and
enhances speech clarity. Subsequently, the surround sound module enhances the
sense of ambiance, redefining the sound aesthetics of vlogging.
With it, strong winds are no match – every frame deserves clear,
warm sound.
·
Status Detection: Conveys noise flags
·
Optional Modules (dashed circle): Not mandatory, for lightweight
adaptation needs
·
Implemented (Awinic blue background): Modules already realized
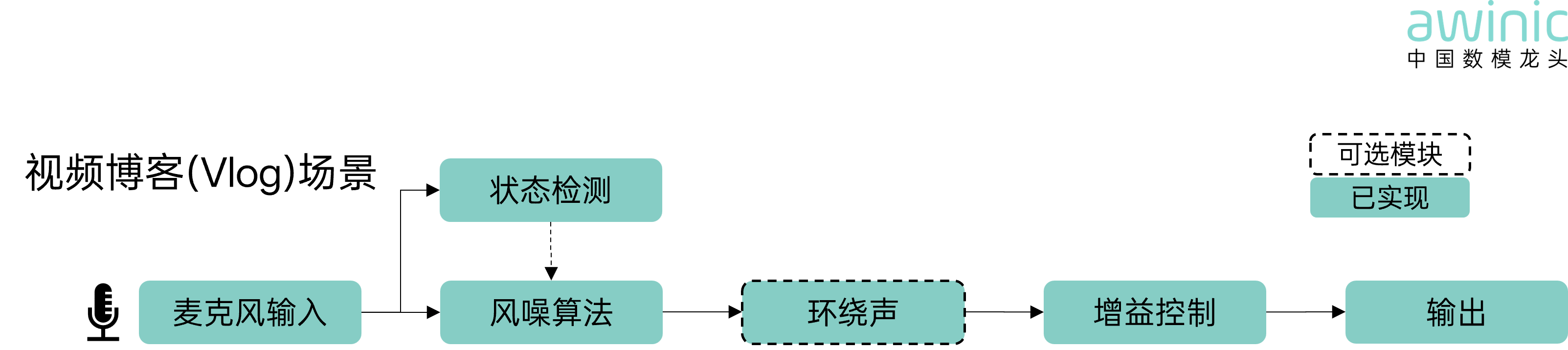
Figure 3: Vlog Scenario Algorithm Block
Diagram
Effect
Demonstration
The wind noise algorithm performs uniquely in different
environments:
✅ No wind & light
wind – Intelligently builds an immersive surround sound field, giving everyday
conversations a cinematic spatial feel.
✅ Strong wind –
Preserves environmental sounds while improving the speech signal's SNR.
It's not about "muting" sounds, but about letting the voice emerge
from the noise and letting the ambiance settle into texture.
2. 🌐 Full-Scenario
Call Empowerment – Intelligent Noise Cancellation, Accurate Voice Transmission
Have you ever experienced this?
💻 In a video
conference, your voice sounds like it's behind frosted glass, and a colleague
frowns and asks, "What did you say?"
🕶️ Taking an
important call on a street, with traffic roaring and horns blaring, the other
person only hears a "hum—";
📝 Communicating
abroad in a noisy environment, the clerk enthusiastically holds up spinach and
says, "Do you like spinach?" but your translation tool interprets it
as "You look like a Spaniard"...

Figure 4: Translation Scenario Demonstration
📞 To address
this, Awinic Dijiang™ delves deep into the full acoustic chain of calls:
The acoustic signals captured by the microphone array are
processed through an echo cancellation module to precisely remove echo
signals. Beamforming acts like an invisible spotlight for sound,
dynamically locking onto the sound source direction and narrowing the effective
pickup area. Finally, noise cancellation blocks external noise, providing an
ultimate calling experience with minimal voice distortion.
· Status
Detection: Conveys noise flags
·
Optional Modules (dashed circle): Not mandatory, for lightweight
adaptation needs
·
Implemented (Awinic blue background): Modules already realized
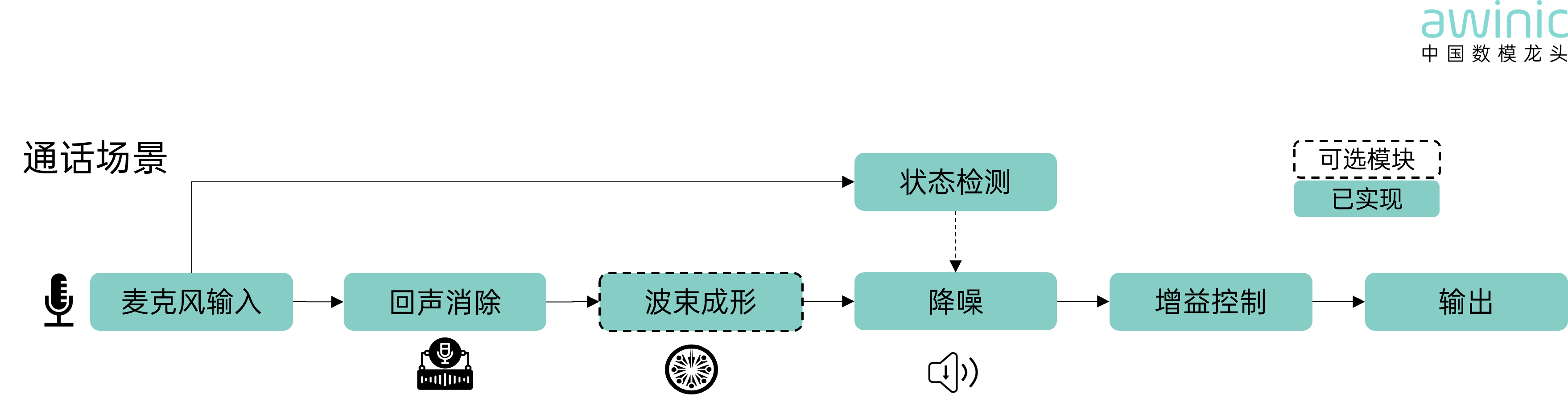
Figure 5: Call Scenario Algorithm Block
Diagram
3. 🗣 The
"First Neural Hub" for Wake-Up Recognition
Have you ever experienced these moments?
🚇 Wearing
glasses on the subway, trying to ask about the weather, but the wind noise
drowns out your voice;
☕ Chatting with friends
in a cafe, you just say "Hey—" and the AI glasses mistakenly trigger;
🕺🏻 Strolling
and casually calling out, the system takes two seconds to respond silently...
Figure 6: Voice Wake-Up Scenario Demonstration
🎤 So, Awinic
Dijiang™ arrives – the front-end voice gatekeeper designed specifically for AI
glasses:
It improves the speech signal-to-noise ratio (SNR) in complex
environments (wind noise, human speech, reverberation). In real-world wearing
scenarios, recognition stability is significantly improved, with a word
error rate reduction of over 6%.
·
Optional Modules (dashed circle): Not mandatory, for lightweight
adaptation needs
·
Planned (grey background): Future roadmap
·
Implemented (Awinic blue background): Modules already realized

Figure 7: Wake-Up Recognition Scenario Algorithm Block Diagram
⏳ Wake-up functionality is no longer just
about "responding when called." Failure to respond is frustrating,
false triggers are embarrassing, and slow reactions are exhausting. User
experience is the sole judge. In the future, Awinic will develop voice wake-up
algorithms featuring ultra-low power consumption and ultra-high wake-up
accuracy. They will be quieter and more sensitive. After all, the best
interaction is when you don't even realize it's working.






